O ano era 2018. Eu tinha acabado de sair de um trabalho como desenvolvedor em uma cooperativa de Salvador e assumido uma posição full-time na Pencillabs. Nessa época, iriamos iniciar o primeiro grande projeto da empresa em parceria com o instituto Cidade Democratica. Este projeto foi desafiador em vários sentidos, mas o que nos interessa aqui é que foi ele quem marcou o início da adoção do Docker Swarm como tecnologia para deploy de aplicações na núvem.
O projeto possuia um arquivo docker-compose.yml, que disponibilizava o ambiente local, e alguns
scripts que automatizavam o ambiente de produção em uma máquina virtual (VPS) na
Digitalocean, mas eu não gostava desta abordagem. Na época eu já
ouvia falar do Kubernetes e o quanto uma infraestrutura
clusterizada poderia facilitar a escalabilidade das aplicações. Comecei então a estudá-lo e cheguei
a conclusão que de fato ele atendia a todos os nossos requisitos de implantação. O nosso maior
problema era a falta de experiência do time com a tecnologia e o tempo que levaria até conseguirmos
definir uma política de deploy utilizando os conceitos do Kubernetes. Nós precisávamos de uma
solução mais simples e é aqui que nossa história com o Swarm começa.
docker stack deploy e docker-compose up
Antes de falarmos do Docker swarm vamos fazer uma pequena revisão do que é um arquivo de compose.
version: "3.0"
services:
db:
image:
postgres:12.2
environment:
- POSTGRES_PASSWORD=ej
- POSTGRES_USER=ej
- POSTGRES_DB=ej
volumes:
- "backups:/var/lib/postgresql/data"
server:
container_name: server
build:
context: ../
dockerfile: docker/Dockerfile
volumes:
- ../:/ej-server/
env_file:
- variables.env
ports:
- 8000:8000
entrypoint: ["/bin/bash", "docker/run_local_server.sh"]
volumes:
backups:
Neste exemplo temos dois serviços: db e server. O serviço db utiliza uma imagem
pronta do postgres, define variáveis de ambiente e monta um volume nomeado. O serviço server
utiliza uma imagem customizada, define variáveis de ambiente a partir de um arquivo .env e monta
um volume do tipo bind. Quando disponibilizarmos o ambiente via docker-compose up o Docker
criará dois containers, um para cada serviço, sendo que o acesso à aplicação poderá ser feito a
partir da url http://localhost:8000. Nada de muito novo aqui.
A primeira grande diferença do Docker swarm para o docker-compose é a forma como o deploy é feito.
No Docker swarm um compose se chama stack e o deploy de uma stack é feito via o comando docker
stack deploy. Como ficaria então o nosso arquivo de compose no formato de stack? Da seguinte
forma:
version: "3.0"
services:
db:
image:
postgres:12.2
environment:
- POSTGRES_PASSWORD=ej
- POSTGRES_USER=ej
- POSTGRES_DB=ej
volumes:
- "backups:/var/lib/postgresql/data"
server:
image: https://registryprivado.com.br/ej-server:latest
volumes:
- code:/ej-server/
env_file:
- variables.env
ports:
- 8000:8000
entrypoint: ["/bin/bash", "docker/run_local_server.sh"]
volumes:
backups:
code:
Notou alguma diferença? Se não, tudo bem, migrar um arquivo de compose para stack é realmente muito simples. Algumas similaridades entre ambos:
- arquivos de stack e arquivos de compose declaram serviços, volumes e redes de forma identica;
- arquivos de stack e arquivos de compose acessam variáveis de ambiente da mesma forma;
Algumas diferenças entre um compose e uma stack:
- arquivos de stack não buildam imagens em tempo de execução. Um serviço criado via
docker stack deploysó pode depender de imagens prontas, disponibilizadas localmente ou em um registry externo como o Dockerhub; - arquivos de stack ignoram algumas opções que podem ser definidas em um compose como build,cap_add, cap_drop, restart entre outras;
- antes de fazer deploy de uma stack é necessário criar um cluster swarm (
docker swarm init);
Essa primeira comparação é para demonstrar o quão simples é sair de um arquivo de compose
(docker-compose up) para um arquivo de stack (docker stack deploy). Mas se é tão simples qual a
vantagem de fazer deploy de aplicações utilizando o modo Swarm? Para responder essa pergunta
precisamos primeiro definir o que é um cluster e de que modo ele pode beneficiar a gestão de
ambientes de produção e homologação.
Escalabilidade e clusterização
Lembra dos nossos serviços criados via docker compose up?
Eles não escalam horizontalmente. Escalabilidade horizontal (de forma bem
resumida) é adicionar mais máquinas para suportar um volume maior de processamento. Em outras
palavras, dividir para conquistar. Em um cenário de grande volume de acessos a uma API, por
exemplo, uma infraestrutura que permite escalabilidade horizontal pode ter várias máquinas pequenas
trabalhando em conjunto. Em um cenário de escalabilidade vertical, a única opção é aumentar o
tamanho da máquina (ram,cpu,disco) para se alcançar uma maior capacidade de processamento.
Tendo esses dois conceitos em mente, serviços criados via docker-compose up não escalam porque o
docker-compose não foi feito para rodar containers de forma distribuida. No
caso do docker-compose podemos utilizar uma abordagem de escala vertical, mas sempre teremos o
limite do tamanho da máquina que o provedor de infraestrutura disponibiliza. Podemos concluir que o
docker-compose é uma ótima ferramenta para desenvolvimento local ou para ambientes mais simples, sem
grande necessidade de escalabilidade. Utilizá-lo para outro fim não é recomendado. Daqui em
diante nosso foco será em como construir uma infraestrutura que escale horizontalmente e tenha
algum nível de tolerância à falha, utilizando o modo Swarm como ferramenta principal.
Segundo a Wikipedia, cluster é “um conjunto de computadores conectados trabalhando em conjunto, de modo que em vários aspectos podem ser vistos como um único sistema”. Cada máquina virtual que compõe um cluster é chamada de nó. Swarm é um modo de execução do Docker para gestão e orquestração de um cluster em que cada nó atua como um manager ou um worker.
No swarm nós que atuam como managers possuem as seguintes responsabilidades:
- manter o estado do cluster: os managers mantêm o estado do cluster e de todos os serviços rodando dentro dele. É recomendável ter um número impar de managers. Caso um manager caia, o estado do cluster é mantido pelos restantes, fazendo com que a infraestrutura seja tolerante a falhas.
- agendamento de serviços: serviços são as partes que compõe uma aplicação (falaremos disso mais a frente). Quando um serviço é criado, é responsabilidade dos managers iniciarem o processo de criação das tarefas que serão executadas pelos workers.
- servir a api http do swarm: os managers são responsáveis por servir os endpoints da api http do swarm. Isso permite integrar a gestão da infraestrutura com outras ferramentas. Um exemplo seria uma plataforma de integração contínua que realiza a atualização do ambiente de homologação por meio da api http.
Os nós que atuam como workers possuem uma única atribuição: executar as tarefas agendadas pelos managers. Um container que existe em um nó é o resultado de uma tarefa disponibilizada por um manager e executada por um worker.
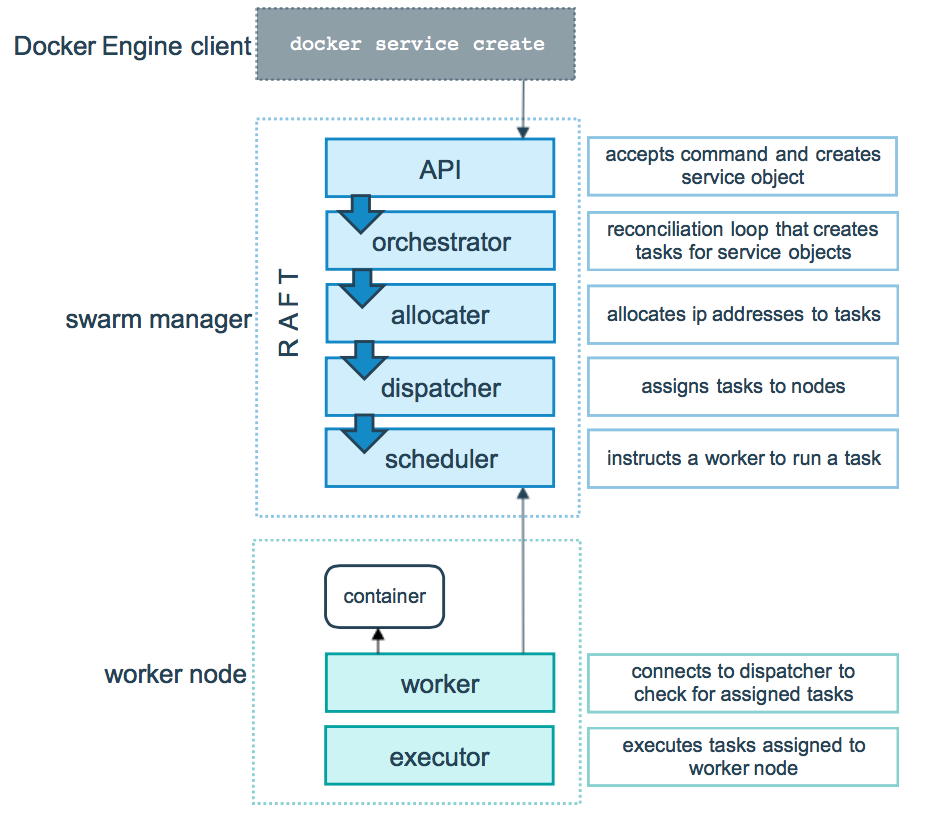
Proposta de arquitetura para micro empresas
Até agora vimos as principais diferenças entre docker-compose e docker stack deploy. A seguir,
um resumo das capacidades de cada estratégia de deploy:
| docker-compose up | docker stack deploy | |
|---|---|---|
| permite criar serviços | sim | sim |
| permite criar volumes do tipo bind | sim | não |
| permite criar volumes nomeados | sim | sim |
| permite comunicação entre os serviços | sim | sim |
| permite distribuir serviços em mais de uma máquina | não | sim |
| permite escalar a aplicação em mais de uma máquina | não | sim |
| permite fazer balanceamento de carga dos serviços | não | sim |
| permite gerenciar diferentes máquinas virtuais de forma unificada | não | sim |
A partir das capacidades do Docker Swarm podemos construir uma política de infraestrutura que permita à micro e pequenas empresas com recursos humanos e financeiros limitados, terem um fluxo de deploy mais profissional com um baixo custo de implantação. Note que, dependendo das especificações do projeto ou das necessidades do cliente, o Docker Swarm não será a melhor opção para a empresa. Uma análise de um especialista em infraestrutura é o melhor caminho para tomar essa decisão. Vamos então propor um cenário de uma aplicação ficticia e, a partir dela, discutir qual seria uma política de infraestrutura mínima para termos escalabilidade, uso eficiente de recursos computacionais e tolerância a falhas.
Imaginemos uma aplicação composta por uma API feita em Django, frontend feito em React e banco de dados postgresql. A primeira definição da nossa estratégia de infraestrutura tem relação ao número de managers e workers. Segundo a documentação do Docker, para alcançarmos um primeiro nível de tolerância à falha o nosso cluster precisa ter no mínimo três nós que atuem como managers. Uma conta simples que pode ser feita é
um cluster com N managers tolera a perda de no máximo (N-1)/2 managers.
Logo, um cluster com três managers pode perder até um manager que o seu estado é mantido sem problemas. Uma infraestrutura com três máquinas, por exemplo, irá precisar de no mínimo três managers e dois workers. Uma das máquinas será apenas manager sendo que as outras duas serão managers e workers.
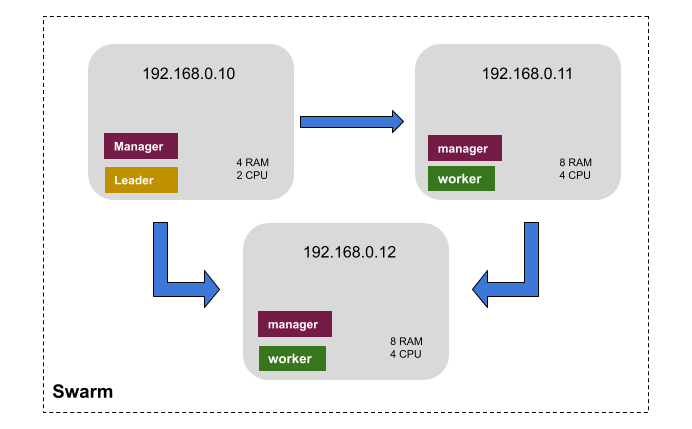
Nessa arquitetura a máquina 192.168.0.10 será exclusiva para gerenciar o cluster.
Isso é importante para não sobrecarrega-la com aplicações que irão
exigir mais recurso. O restante das máquinas atuarão como worker e caso o manager principal caia, o
estado do cluster se mantem operacional. Dada esta organização podemos distruibuir os
serviços da aplicação nas máquinas 192.168.0.11 e 192.168.0.12. A seguir, apresentaremos alguns
cenários de uso do cluster.
Cenário 1
API rodando na máquina 192.168.0.11, banco de dados e frontend rodando na máquina 192.168.0.12.
Um cenário simples, que tira pouco proveito das principais capacidades do Swarm, mas que permite
algum nível de independência entre os serviços da aplicação.
Cenário 2
API rodando de forma replicada nas máquinas 192.168.0.11 e 192.168.0.12, banco de dados e
frontend rodando na máquina 192.168.0.12. Em um cenário de aumento de volume de acessos na API, o
Swarm fará o load balancing entre as máquinas 192.168.0.11 e 192.168.0.12. Replicas são
containers que utilizam uma mesma imagem e são controladas pela camada de serviço do Docker. Um
serviço com 5 replicas, por exemplo, terá 5 containers rodando no cluster.
Cenário 3
API rodando de forma replicada nas máquinas 192.168.0.11 e 192.168.0.12, banco de dados e
frontend rodando na máquina 192.168.0.12. Em um cenário de aumento de volume de acessos na API, o
Swarm fará o load balancing entre as máquinas 192.168.0.11 e 192.168.0.12, mas duas máquinas não
são mais suficientes para manter a aplicação responsiva. Neste cenário precisaremos adicionar mais
máquinas ao cluster. Utilizando a capacidade do Swarm de forçar serviços à sempre subirem em
máquinas específicas,
podemos escalar os serviços da stack de forma independente, o que permite um melhor uso de recursos
computacionais. Escale apenas o que for necessário, quando for necessário.
Conclusão
Obrigado por chegar até aqui. Meu objetivo com este artigo é te apresentar uma ferramenta acessível que permita dar os primeiros passos no estudo e aplicação de conceitos como: escalabilidade, tolerância a falhas, dimensionamento de infraestrutura e redes. Como vimos, migrar um arquivo de compose para uma stack e começar a realizar testes com um cluster Swarm é bastante simples. A documentação do Docker é bem completa e cobre bem os cenários de uso que discutimos aqui. O foco deste artigo não foi fazer um comparativo entre Swarm e Kubernetes (talvez isso venha em um novo artigo). O Kubernetes foi feito para resolver problemas de escalabilidade de empresas como Google. Vale refletir se o estágio de maturidade do seu negócio exige uma plataforma como o Kubernetes ou se o Swarm pode ser uma saída mais barata e que entregue valor.