essa publicação é uma repostagem de um artigo publicado no medium. Algumas informações foram atualizadas.
Sou cofundador e engenheiro de software na Pencil Labs, uma empresa de Brasília fundada em 2016. Esse é o primeiro conteúdo relacionado ao trabalho que temos desenvolvido ao longo desses anos. Esse artigo é um breve relato de como tem sido minha experiência em prover infraestrutura para os projetos da Pencil, utilizando um modo de execução do Docker chamado swarm, integrado a um servidor de arquivos NFS.
PencilLabs
Atualmente, a Pencillabs é composta por três frentes de trabalho:
SocialProtection.org: plataforma de referência mundial no âmbito da Proteção Social. A stack da plataforma é formada por:
- CMS feito em Drupal (PHP);
- Mysql como banco de dados;
- Solr para indexação dos dados;
Empurrando Juntos (EJ): plataforma de consultas de opinião desenvolvida em software livre com foco em Estado e Organizações. A stack da plataforma é formada por:
- Aplicação monolítica feita em django e jinja2;
- Postgresql como banco de dados;
- Infraestrutura de ML para chatbots utilizando Rasa;
- Infraestrutura para coleta de dados com framework Airflow;
Prestação de serviço de desenvolvimento e manutenção: além dos projetos da casa, também prestamos serviço para empresas e organizações, que desejam desenvolver produtos digitais para seus negócios. Trabalhamos também com migração de infraestrutura para ambientes Docker.
Pensar em uma infraestrutura que suportasse essas três frentes de trabalho, nos levou a escolher o modo Swarm do Docker, para orquestrar nossos containers na nuvem. Antes de apresentar o que foi feito para viabilizar tal infraestrutura, devo dizer que consideramos utilizar o Kubernetes, projeto desenvolvido pelo Google e que também atua como um orquestrador de containers. O modo swarm já é nativo da engine do Docker, não havendo necessidade de nenhuma instalação ou configuração para iniciar o processo de clusterização. Como já usávamos Docker em produção, essa facilidade em dar os primeiros passos com o modo swarm foi o principal fator para a sua adoção.
Docker Swarm
Segundo a Wikipedia, cluster é “um conjunto de computadores conectados trabalhando em conjunto, de modo que em vários aspectos podem ser vistos como um único sistema”. Cada máquina virtual que compõe um cluster é chamada nó. Swarm, é um modo de execução do Docker para gestão e orquestração de um cluster, em que cada nó atua como um manager ou um worker.
No swarm, nós que atuam como managers possuem as seguintes responsabilidades:
- Manter o estado do cluster: os managers mantêm o estado do cluster e de todos os serviços rodando dentro dele. É recomendável ter um número impar de managers. Caso um manager caia, o estado do cluster é mantido pelos restantes, fazendo com que a infraestrutura seja tolerante a falhas.
- Agendamento de serviços: serviços são as partes que compõe uma aplicação (falaremos disso mais a frente). Quando um serviço é criado, é responsabilidade dos managers iniciarem o processo de criação das tarefas executadas pelos workers.
- Servir a api http do swarm: os managers são responsáveis por servir os endpoints da api http do swarm. Isso permite integrar a gestão da infraestrutura com outras ferramentas. Um exemplo seria uma plataforma de integração contínua que realiza a atualização do ambiente de homologação por meio da api http.
Os nós que atuam como workers possuem uma única atribuição: executar as tarefas agendadas pelos managers. Um container que existe em um nó, é o resultado de uma tarefa disponibilizada por um manager e executada por um worker.
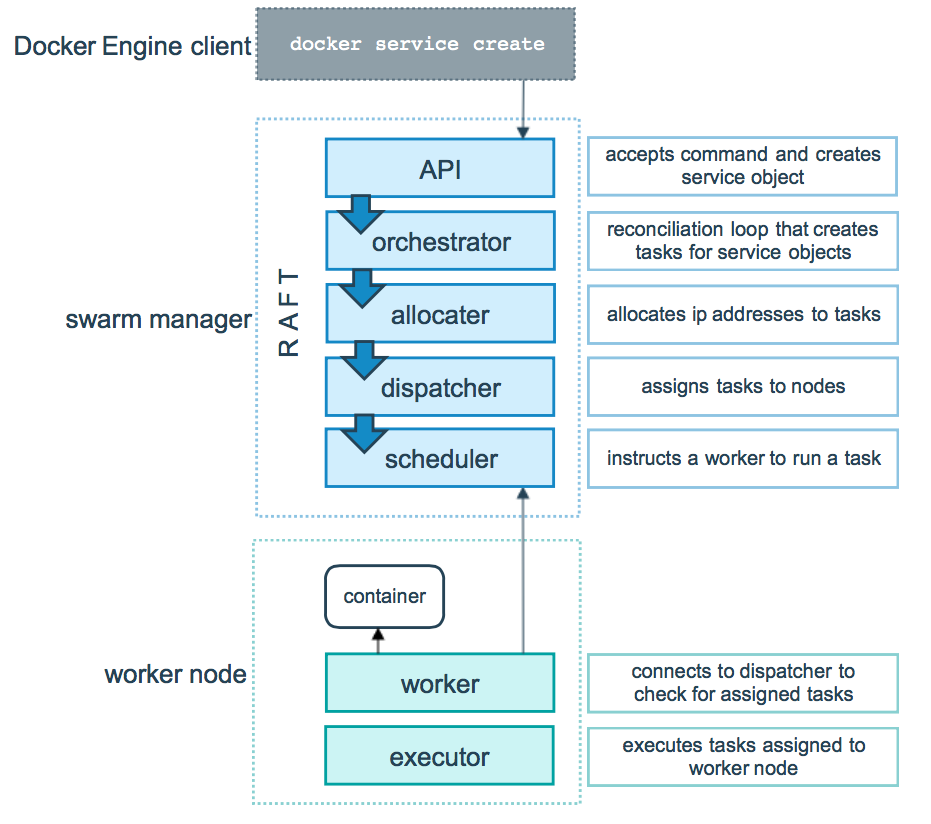
Do ponto de vista do Docker cada “pedaço” da aplicação é considerado um serviço que será executado dentro do swarm. Por exemplo, uma aplicação composta por um servidor web e um banco de dados, irá possuir dois serviços, um para cada parte da aplicação. Vale ressaltar que um serviço não é o mesmo que um container. A documentação do Docker explica que serviços são “containers em produção”, mas como ambos os termos serão utilizados ao longo do texto, podemos considerar que um serviço define como os containers serão executados. A partir de qual imagem o container será criado, as portas que serão exportadas, o número de réplicas que esse serviço possuirá, entre várias outras configurações que definidas ao nível de serviço, mas que refletem diretamente nos containers. Todas essas configurações podem ser definidas por meio do arquivo docker-compose.yml.
version: "3"
services:
web:
# replace username/repo:tag with your name and image details
image: username/repo:tag
deploy:
replicas: 5
restart_policy:
condition: on-failure
resources:
limits:
cpus: "0.1"
memory: 50M
ports:
- "80:80"
networks:
- webnet
visualizer:
image: dockersamples/visualizer:stable
ports:
- "8080:8080"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
deploy:
placement:
constraints: [node.role == manager]
networks:
- webnet
networks:
webnet:
Docker stack
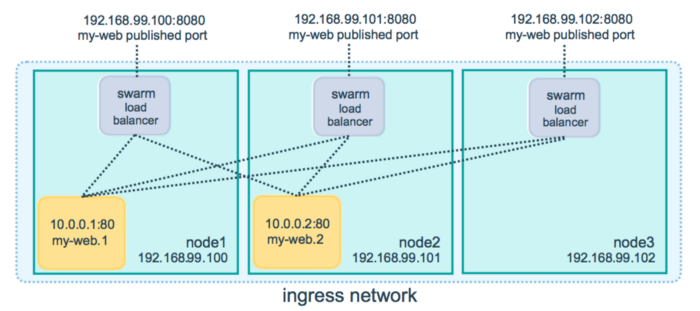
Para fazer o deploy dos serviços descritos no exemplo anterior, bastaria (fazendo as devidas adaptações ao exemplo) executar o comando docker-compose up. O problema dessa abordagem é que ela não escala ao longo dos nós da infraestrutura, ou seja, os serviços criados a partir do docker-compose up não são compatíveis com o modo swarm. Para realizar o deploy dos serviços no swarm é necessário utilizar o comando docker stack deploy. Uma stack descreve todos os serviços que compõe uma aplicação. Isso permite realizar o deploy destes serviços ao longo dos nós do swarm. Caso a aplicação precise de mais recurso, basta adicionar mais um nó ao swarm e aumentar o número de réplicas. No diagrama a baixo, my-web é o nome do serviço. Esse serviço possui duas replicas (containers), my-web.1 e my-web.2 . Cada replica é executada em um nó diferente e cada replica possui um ip único dentro do swarm.
Proxy Reverso
O fato de uma aplicação poder ser executada em qualquer nó do swarm e ainda assim ser acessada pelo cliente de modo transparente, impacta como o servidor http interage com os serviços. O nginx, quando configurado como um proxy reverso, irá redirecionar requisições externas ao servidor para as aplicações executadas no servidor. Isso irá acontecer independente de se utilizar o modo swarm ou não, o que muda é de que forma esse redirecionamento interno irá acontecer.
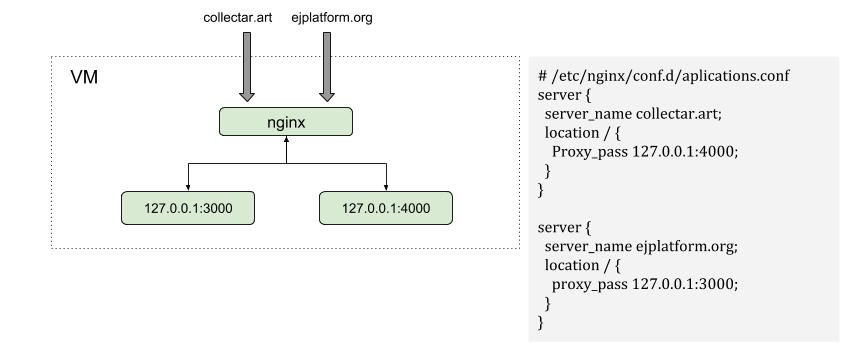
Uma aplicação executada fora do swarm, e utiliza nginx como servidor http, irá ser servida conforme o esquemático a seguir. As requisições irão chegar na porta 80 ou 443, e a partir do domínio da requisição o nginx irá redirecionar para a porta e ip correspondentes ao domínio requisitado. Esse é o modus operandi de uma aplicação que não é servida de maneira clusterizada.
Por outro lado, uma aplicação executada no modo swarm, e utiliza nginx como servidor http, irá ser servida conforme o próximo esquemático. As requisições irão chegar na porta 80 ou 443, e a partir do domínio da requisição o nginx irá redirecionar para o serviço correspondente ao domínio requisitado. Note que, assim como as aplicações, o nginx também é executado como um container dentro do cluster. O nginx utiliza o nome do serviço para realizar o proxy reverso. O servidor DNS que existe dentro do swarm resolve o nome do serviço definido na diretiva proxy_pass para o ip de algum container que pertença ao serviço.
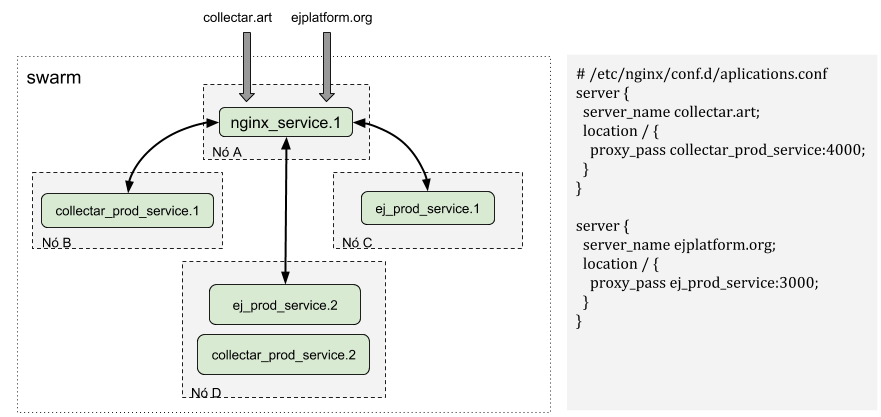
Se tivermos, por exemplo, cinquenta replicas do serviço do EJ sendo executadas no swarm, nada muda para o nginx. É papel do swarm realizar tanto o load balancing quanto a resolução do nome do serviço para o ip do container.
Arquivos Estáticos e NFS
Devido à natureza clusterizada do modo swarm, os containers dos serviços podem rodar em qualquer nó do cluster. Isso é muito importante, pois nos permite escalar horizontalmente (adicionando mais nós ao swarm). Como os containers podem rodar em qualquer nó, os arquivos estáticos (html,css,js) das aplicações vão existir apenas no nó em que o container estiver rodando, e isso é um problema para o nginx. Para servir os arquivos estáticos das aplicações o nginx precisa ter acesso de leitura aos arquivos, mas se o nginx estiver rodando no nó A e a aplicação estiver rodando no nó B, esse acesso não será possível. Para contornar esse problema nossa infraestrutura conta com um servidor NFS, que permite que o nginx acesse os estáticos de uma aplicação mesmo que ambos estejam rodando em nós diferentes. O proposito de um servidor NFS é permitir que o cliente acesse via rede, diretórios e arquivos existentes no servidor, como se esses arquivos existissem também no cliente.
Analisando brevemente um dos nós da infraestrutura, temos a seguinte organização dos discos. Em vermelho temos o disco da máquina virtual. Ele possui 241 gigas. Em verde temos diretórios montados via NFS. A configuração do servidor ocorre da seguinte forma: no servidor você define as regras de quem irá poder montar as partições via rede. Essas partições são os diretórios que existem na máquina virtual em que o servidor NFS está sendo executado. No cliente, via comando mount, você monta um diretório existente no servidor.
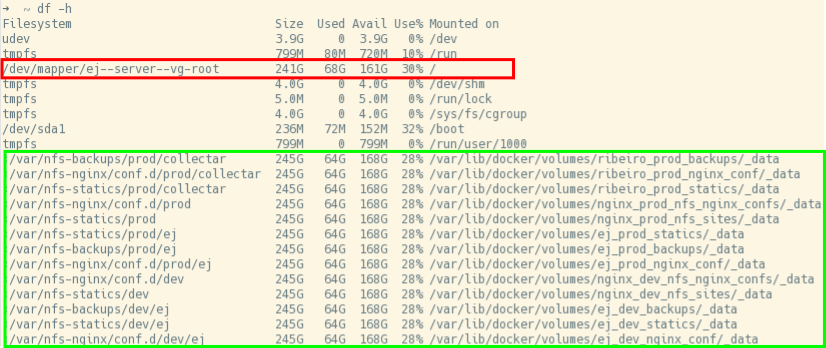
Os arquivos existentes no servidor estarão disponíveis no cliente, e este poderá alterar, modificar e até criar arquivos, que automaticamente serão sincronizados no servidor. Note que, os diretórios são montados como uma partição da máquina. A partição vai ter o tamanho da máquina virtual em que o servidor NFS está sendo executado. De maneira prática os arquivos existem apenas no servidor, se um cliente desmonta uma das partições os arquivos deixam de existir apenas no cliente.
Por padrão o Docker sempre monta os volumes na máquina local. Para que o Docker monte os volumes no servidor NFS temos que, via arquivo de configuração, informar algumas opções como o ip do servidor, o modo de acesso (escrita e leitura) e qual o device (diretório) será montado. Note que o device deve existir no servidor NFS antes de tentarmos fazer o deploy da stack. Isto é uma limitação do driver do Docker, pois, caso o diretório informado não exista, o serviço não vai inicializar corretamente.
volumes:
backups:
driver: “local”
driver_opts:
type: nfs
device: :/var/nfs-statics/dev/ej
o: addr=192.168.0.231,rw
O esquemático a seguir demonstra de que forma ocorre a relação entre uma instância do nginx, uma instância de uma aplicação com arquivos estáticos e o NFS. Inicialmente o nginx irá montar no servidor NFS o diretório /var/nfs-statics/dev/, que irá conter subdiretórios que serão montados pelas aplicações. Quando for feito o deploy do EJ, o volume ej_dev_statics será montado no NFS, sincronizando o diretório /ejserver/local com o diretório /var/nfs-statics/dev/ej/ . Nesse momento vale ressaltar uma particularidade do NFS: Um cliente pode acessar todos os subdiretórios do diretório montado, mas os diretórios acima da raiz não são acessíveis. O volume do EJ não tem acesso ao diretório /var/nfs-statics/dev/, já que este está acima do diretório montado pelo Docker. Por outro lado, qualquer pasta criada dentro de /var/nfs-statics/dev/, será acessível pelo nginx.
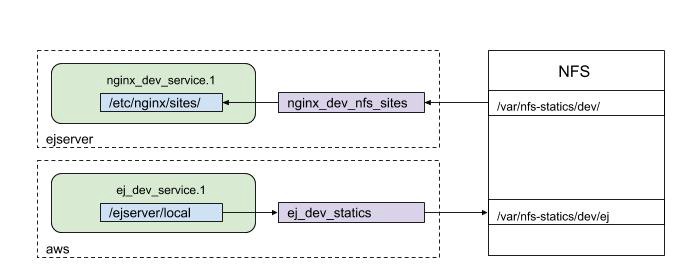
Logo que os arquivos estáticos forem gerados no container do EJ, o Docker irá monta-los no NFS dentro de /var/nfs-statics/dev/ej/ (até então esse diretório estava vazio). Ao montar os arquivos estáticos no NFS, automaticamente eles também existirão dentro do container do nginx, já que o diretório /var/nfs-statics/dev/ej é um subdiretório de /var/nfs-statics/dev/. Resumindo, qualquer arquivo ou diretório criado dentro de /ejserver/local também existirá dentro de /etc/nginx/sites/ej/. Ao final do deploy da stack do EJ, teríamos os seguintes diretórios dentro do container do nginx e do servidor do EJ:
# no container do EJ
$ ls /ejserver/local/
html css js # no diretório do ej no NFS
$ ls /var/nfs-statics/dev/ej/
html css js # no container do nginx
$ ls /etc/nginx/sites/
ej
$ ls /etc/nginx/sites/ej/
html css js
Quando o nginx consegue acessar os arquivos estáticos das aplicações, através de um volume montado no servidor NFS, nosso problema está resolvido. Agora que sabemos como um servidor NFS funciona e de que forma podemos montar os volumes via rede, o esquemático final da nossa infraestrutura é o seguinte:
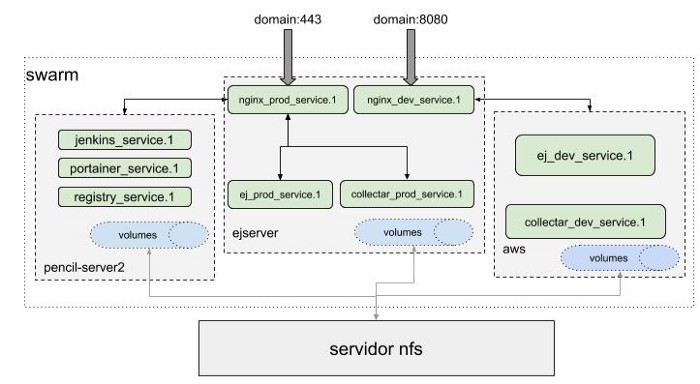
As requisições irão chegar ao swarm nas portas 80 e 443 (produção) e 8080 (homologação). Uma instância do nginx irá responder à essas requisições, identificando o domínio e, em seguida, redirecionando para o devido serviço. Cada aplicação com arquivos estáticos irá montá-los no NFS, em subdiretórios dos diretórios montados pelo nginx. Dessa forma as aplicações são executadas em qualquer um dos nós, e ainda assim o proxy reverso será feito e os arquivos estáticos serão servidos.
Conclusão
Primeiramente gostaria de agradecer por acompanhar até aqui. Essa foi minha primeira publicação técnica, então obrigado dedicar parte do seu tempo para essa leitura. A arquitetura que apresentamos permitiu colocar em produção, para cada um dos projetos da Pencil, dois ambientes totalmente isolados. Tanto EJ quanto Collectar possuem ambientes de produção e homologação. Além destes projetos, nossa infraestrutura também possibilita criar ambientes de produção e homologação para outros clientes da empresa.
Apesar de resolver alguns problemas, esse arranjo da infraestrutura trouxe outras questões como:
qual o impacto do modo swarm integrado a um servidor NFS, no desempenho das aplicações?
Uma análise de desempenho nessa arquitetura é necessária, uma vez que não sabemos se essa abordagem aumentou o tempo de resposta das aplicações. Tal análise ficará para uma próxima conversa.
Se interessou pelo nosso trabalho e tem desejo de desenvolver produtos digitais como aplicativos e sites? Entre em contato pelo nosso site, ou nos envie um email em contato@pencillabs.com.br. Somos pessoas especializadas em desenvolver produtos digitais que geram o salto estratégico que sua organização precisa.